🌲 WTSFest Portland - May 2026 | 🥨 WTSFest Philadelphia - Oct 2026 | 🎥 On-Demand Video Hub - 2026
🌲 WTSFest Portland - May 2026 | 🥨 WTSFest Philadelphia - Oct 2026 | 🎥 On-Demand Video Hub - 2026

Author: Gianna Brachetti-Truskawa
Last updated: 20/03/2024

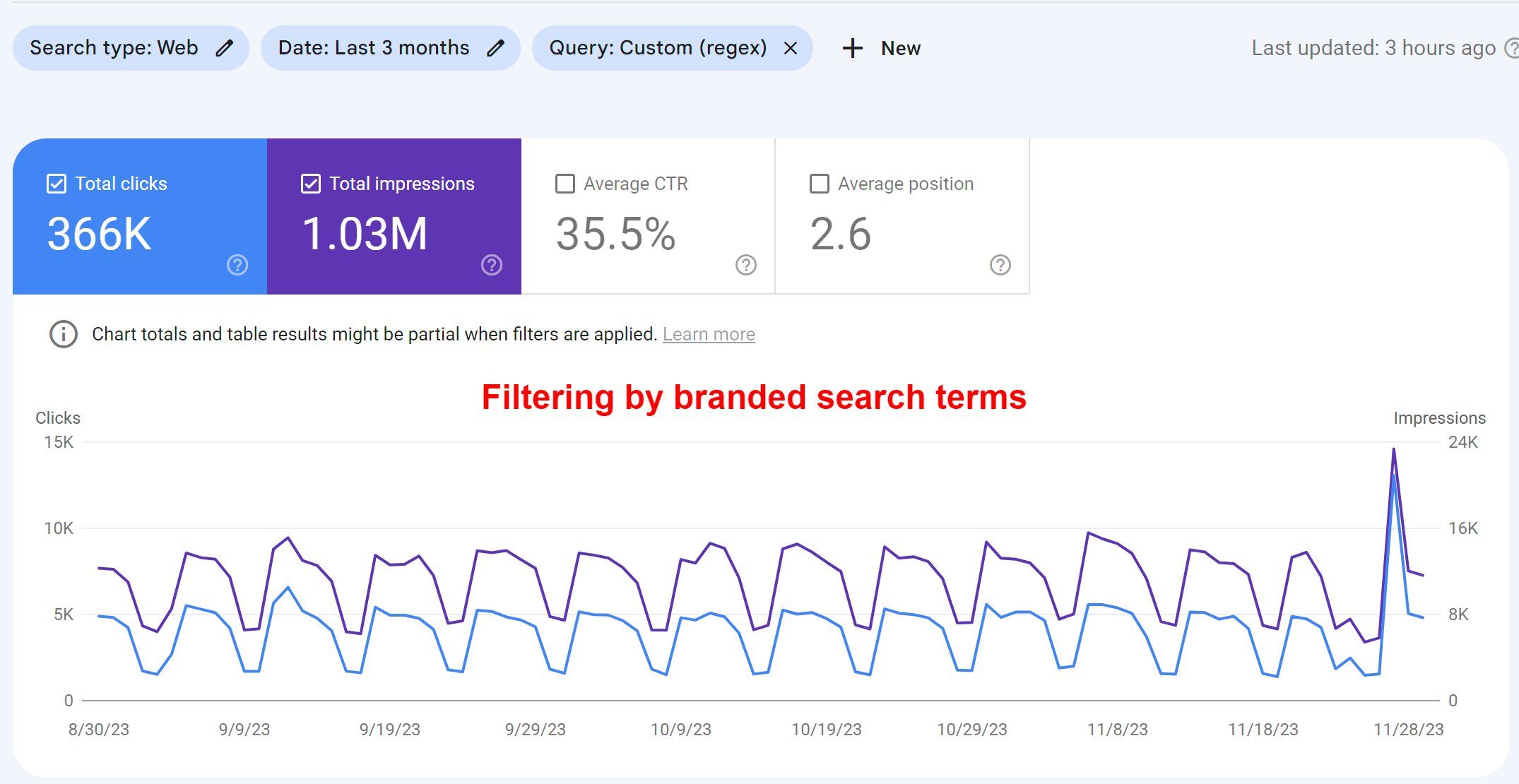
We all meet at the same crossroads. Suddenly, dozens, hundreds, or millions of URLs are stuck in the dreaded Discovered, not crawled, or Crawled not indexed death zone in Google Search Console (GSC).
Many SEOs won’t bother with this death zone until the number of pages deemed to not be index-worthy exceeds indexed URLs. Except that we all keep on running into new and old patterns in GSC that keep us from achieving greatness and fixing the dreaded issue. Collective frustration has reached a point where it’s time to address the matter. Think of it as a therapy session for the entire industry. A deep dive into the darkness of GSC.
Read on if you dare, but beware: you might never look at GSC the same way again.
● It gives you wrong or incomplete data about your site's performance, indexation, crawling, and errors. Sometimes it even contradicts itself, or changes its labels without warning.
● Google deprecate or remove useful tools that help you troubleshoot and fix issues. Sometimes replacing them with inferior ones or none at all.
● You have to wait for ages to see the results of your fixes or changes. Sometimes it stops validating or reporting altogether.
● It limits your access and control over your site's data. You can't export, filter, or query everything you need. You can't manage multiple properties or users easily. You can't trust the API or the UI to give you the same data.
● It confuses and frustrates you with its cryptic error notifications, obscure regex syntax, and inconsistent data retention. You can't rely on it as your single source of truth.
So what can you do? Complement GSC with other tools and testing methods. Learn how to analyse your server logs, render your pages, monitor your site health, and understand your traffic. And read this article to see all the exhibits of GSC's flaws and how to overcome them.
We will now walk through 11 exhibits showcasing the key flaws we frequently encounter with Google Search Console.
After fixing the cause of the above-mentioned issue, in an attempt to clean up Google's crawl queue we set all of the unworthy URLs to HTTP status code 410. I have long been a proponent of setting URLs to 410 for two reasons:
Until the latter did not work anymore.
Which makes you wonder if they started to treat 410 errors the same as 404s. At the time of writing this article, I could not find proof they would.
According to their documentation:
"All `4xx` errors, except `429`, are treated the same: Googlebot signals the indexing pipeline that the content doesn't exist."
And Google’s guide for 404 errors states clearly that they treat 410s the same as 404s - but to this day I have not found a single instance in their documentation confirming that 410s would be reported as 404s in Google Search Console:

Another location where you may find reporting about 4xx status codes are the Crawl Stats. Documentation for the Crawl Stats report. But, this also does not mention specifically where you could expect to see if the crawler found any 410 errors:
There is a reason why we have different types of error codes, however. It would be preferable if Google did not treat them all the same, as people set them for different purposes; or at the very least, if Google stopped confusing us by claiming they were all 404s and instead showed the actual HTTP status code they received at the last time they tried to access the URL.
The IETF defines this error code as follows:
"The 410 (Gone) status code indicates that access to the target resource is no longer available at the origin server and that this condition is likely to be permanent."
And:
"The 410 response is primarily intended to assist the task of web maintenance by notifying the recipient that the resource is intentionally unavailable and that the server owners desire that remote links to that resource be removed."
Yes, the good news is: 410s will still speed up the cleanup of the crawl queue and have any indexed URLs deindexed soon. Google remain a bit ambiguous, saying that they might clean up 410s earlier than 404s but that this is rather a couple of days faster than 404s. In our experience (as of autumn 2023), it still works considerably faster.
If you keep 404s unresolved for too long, they too will be removed from the index whether you want it or not. Therefore it would be a great help to SEOs if GSC would correctly distinguish between 404s and 410s, so that unintended 404s can be fixed before pages they might want to keep are removed from the index.
I do not know why Google decided to no longer classify 4xx errors correctly. There are rumours it might be due to how much they rely on cache, as explained by Simone de Palma:
“It’s not confirmed but the issue with misleading reporting (...) - is due to Google massively relying on cache for crawl stats reports.”
Also see the most recent discussion in the Search Console Help Community.
This is not the indexation status you are looking for.
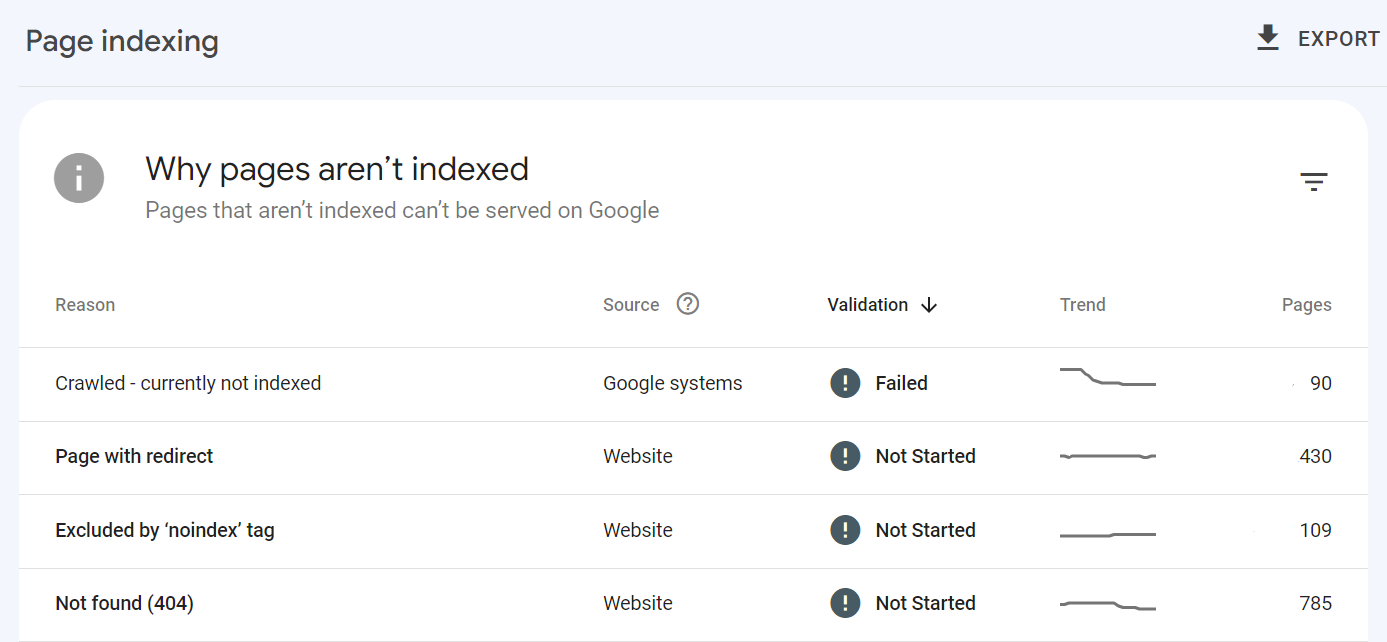
First of all: You cannot filter for specific URL types in this report, which is quite annoying, as you might want to exclude those that you do not want indexed anyway. If you need to filter, you have to export to a file format of your choice and sort the table by yourself.
What’s worse is that you cannot even trust what it shows you:
This list of URLs in the Crawled, Not Indexed report suggests they are not indexed as of their most recent crawl date.

Yet some appear indexed according to the URL Inspection tool two days later:
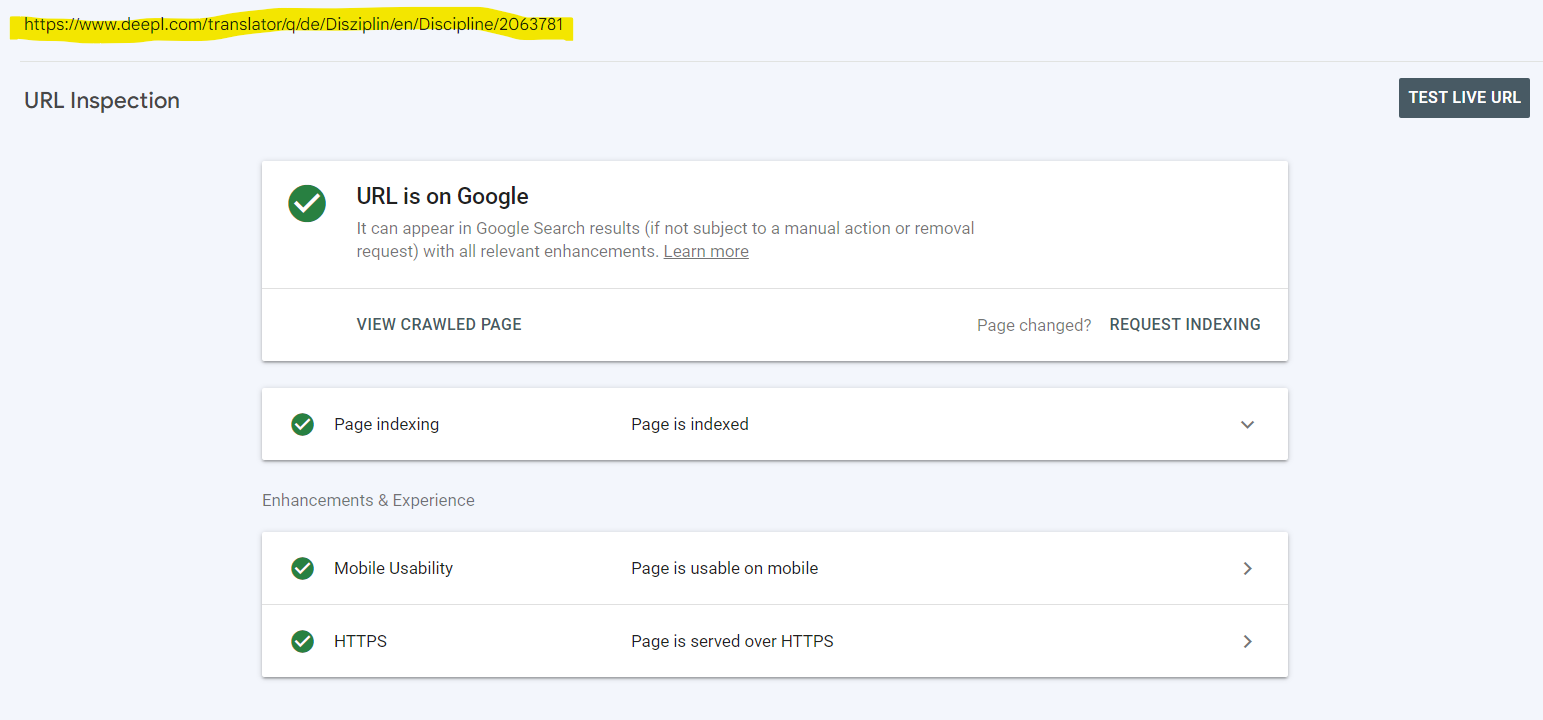
You would think the page got indexed between the crawl date and when I checked — except the URL Inspection shows the same latest successful crawl date as when the page showed in the report as not indexed – i.e. the URL inspection dialogue tells us it has last been crawled - and successfully so - the 28.11.2023:
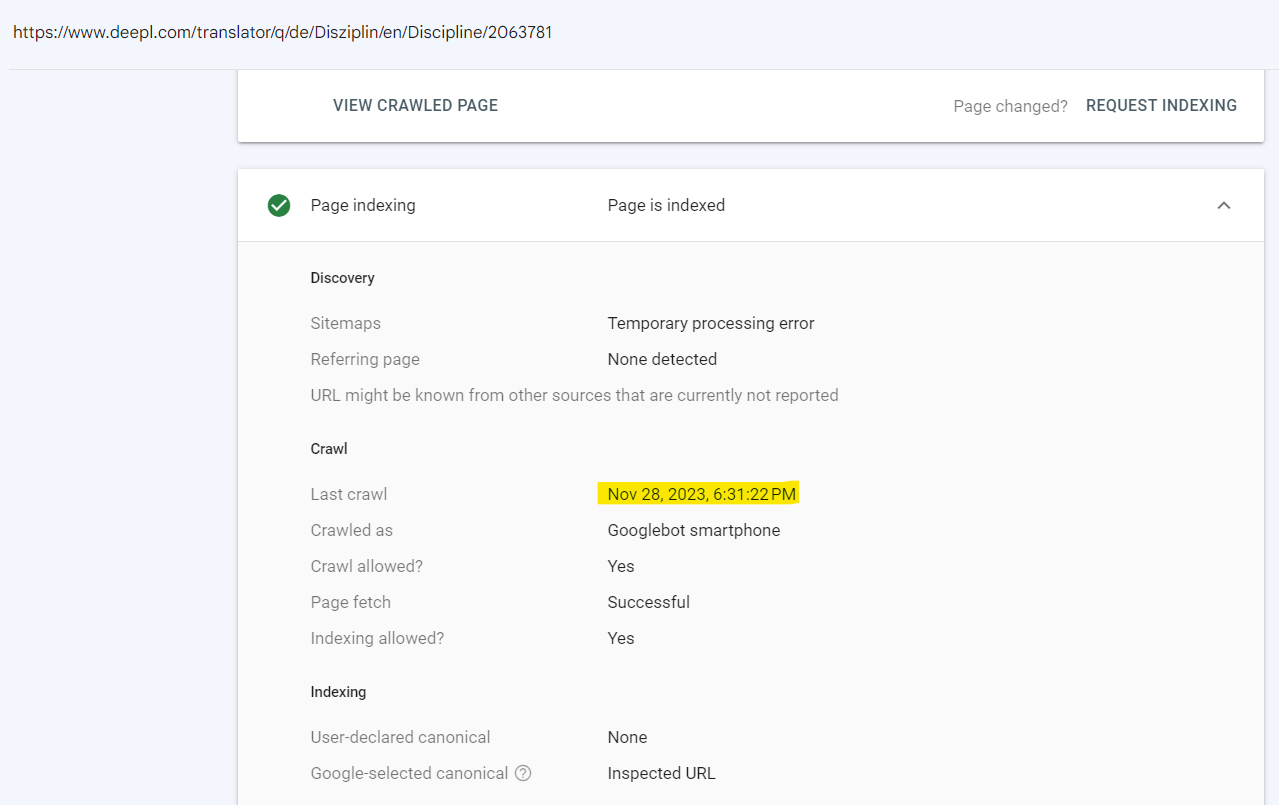
We can also find the URL in Google Search - another indicator that at least what the URL inspection tells us about the URL’s indexation status is true.
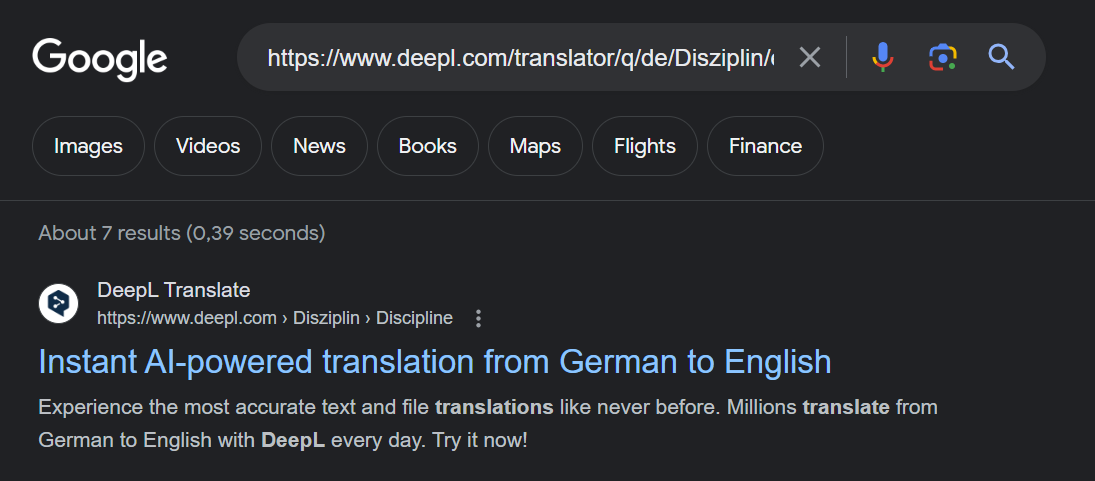
Another URL from the list at the beginning of this chapter: Allegedly not indexed as per 28.11.2023, yet upon inspection, indexed as per the last crawl on the same date:
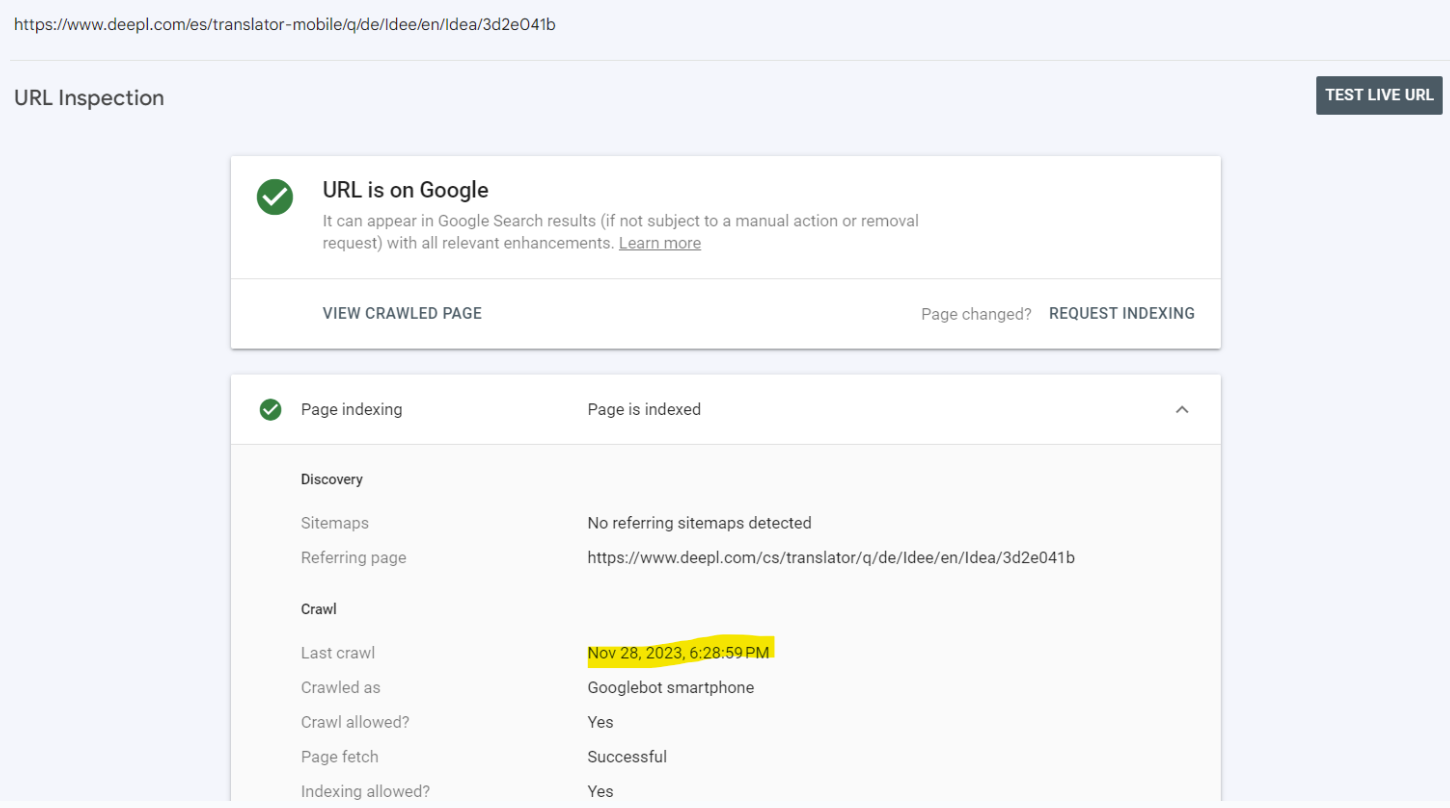
Here is another fun one - technically not a flaw of GSC, but when you have to resort to other methods to verify if what GSC reports as an error, really is one, you might end up in Google Search, e.g. to check if and when a page has been last cached.
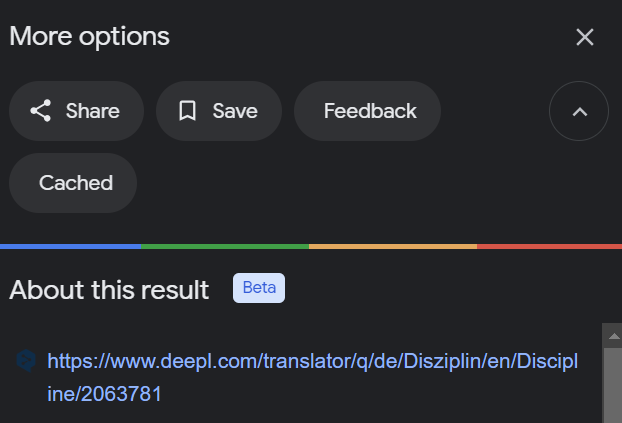
Which would be great if it was actually working and not telling it has been cached, only to end up in a 404 on Google’s end. (While writing this article, we asked Search Console nicely to show us the cached date of a few of our pages, but it refused, insisting on being difficult. Another issue for another article time.)
If this worked, it should be looking something like the image below, where Google shows a small overlay on top of the page, indicating the date of when the page was last cached, plus a rendered version of the cached page, as well as allowing you to inspect the source code.
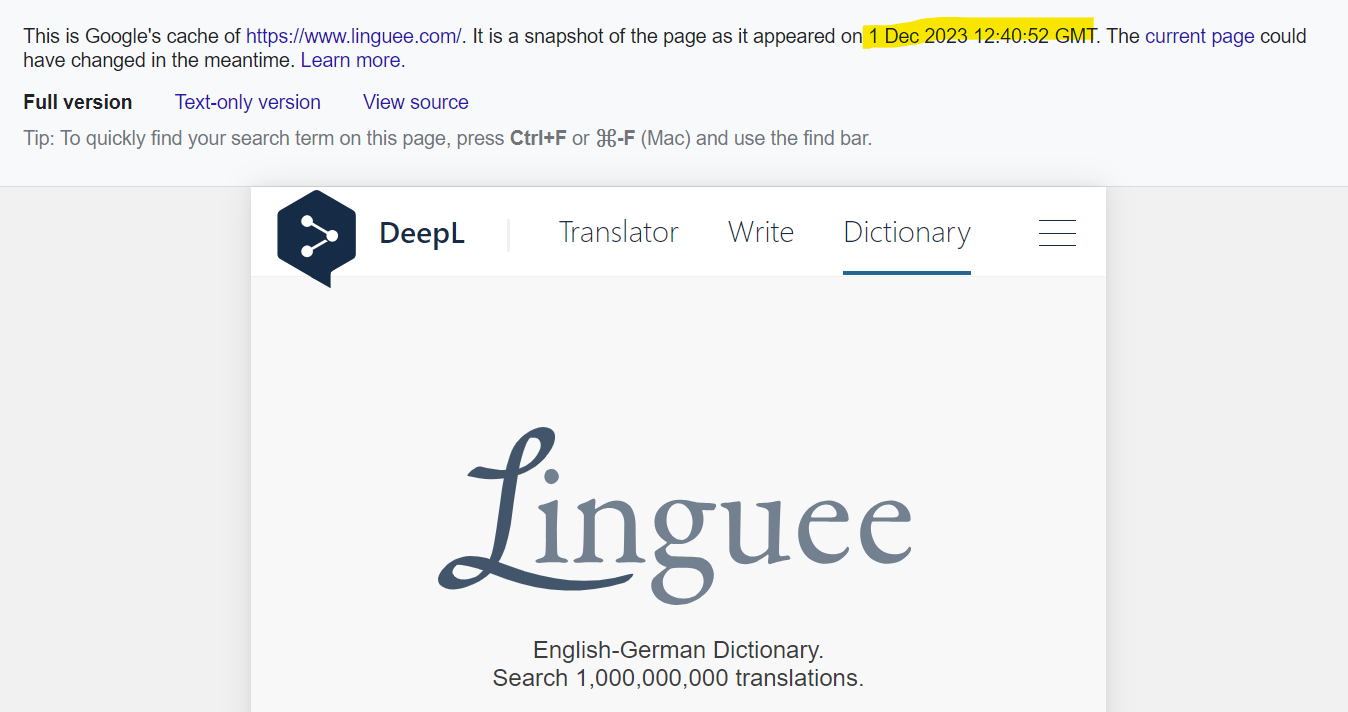
Probably more of a usability issue but what really gets me every single time is when I know Google have the data I want but either won’t give it to me at all - or make me click a few times to get it.
If you use URL Inspection, you can see when a URL was last crawled - but this might not be the version they decided to cache and show in the search results. How would you know? They do not show the cache date in URL Inspection.
To view the cache date, you’ll annoyingly have to:
(If this actually worked and did not end up in 404s on Google’s end!)
What? Is this not your definition of fun?

If you are a publisher who depends on Google indexing and showing your most current version of a page, you end up doing this way more often than I’d consider healthy.
While I was hoping the cached data might eventually become available via Search Console API, or visible in Search Console itself - Google have announced recently that they may deprecate cache altogether, starting with removing the cache link by the end of January 2024.
Another case of the URL Inspection being rather obscure: Let’s say you have a page with regular organic traffic, (so it must be indexed), and wanted to find additional information via the URL Inspection in GSC… imagine the sheer panic it can send you into if it claims that Google does not know this URL.
Take the example by Matt Tutt below — Crawl Stats say it was last crawled by Googlebot Smartphone. But press "Live Test URL" and Search Console claims it's never seen the URL!
Which is it, Google? Did you crawl this page or not?
Schrödinger’s Crawl strikes again - to know if Google truly crawled a page, you will learn how to analyse your server access logs.
Search Console API to the rescue! Fetching the date when a URL was last crawled requires you to send a request to the Search Console API, and comes with limitations. SEOs for large domains might have to orchestrate their API calls carefully to not exceed the URL inspection limit of 2,000 calls per day.
TIP: Divide your domain into multiple properties to circumvent this limit!
If you do not know how to send requests to Search Console API, our beloved Swiss Army Knife aka Screaming Frog Spider can help you. By temporarily allowing access to your properties in GSC, it can fetch the data for you. If it does not work properly, however, we suspect you might get the same results that you see when asking for a URL manually in GSC’s frontend.

We tested the results of GSC API for a small sample of URLs that were reported as Crawled, not indexed and shown as indexed as per the URL Inspection tool, and got the same results as in the frontend.
If the above examples weren’t enough - we have one more:
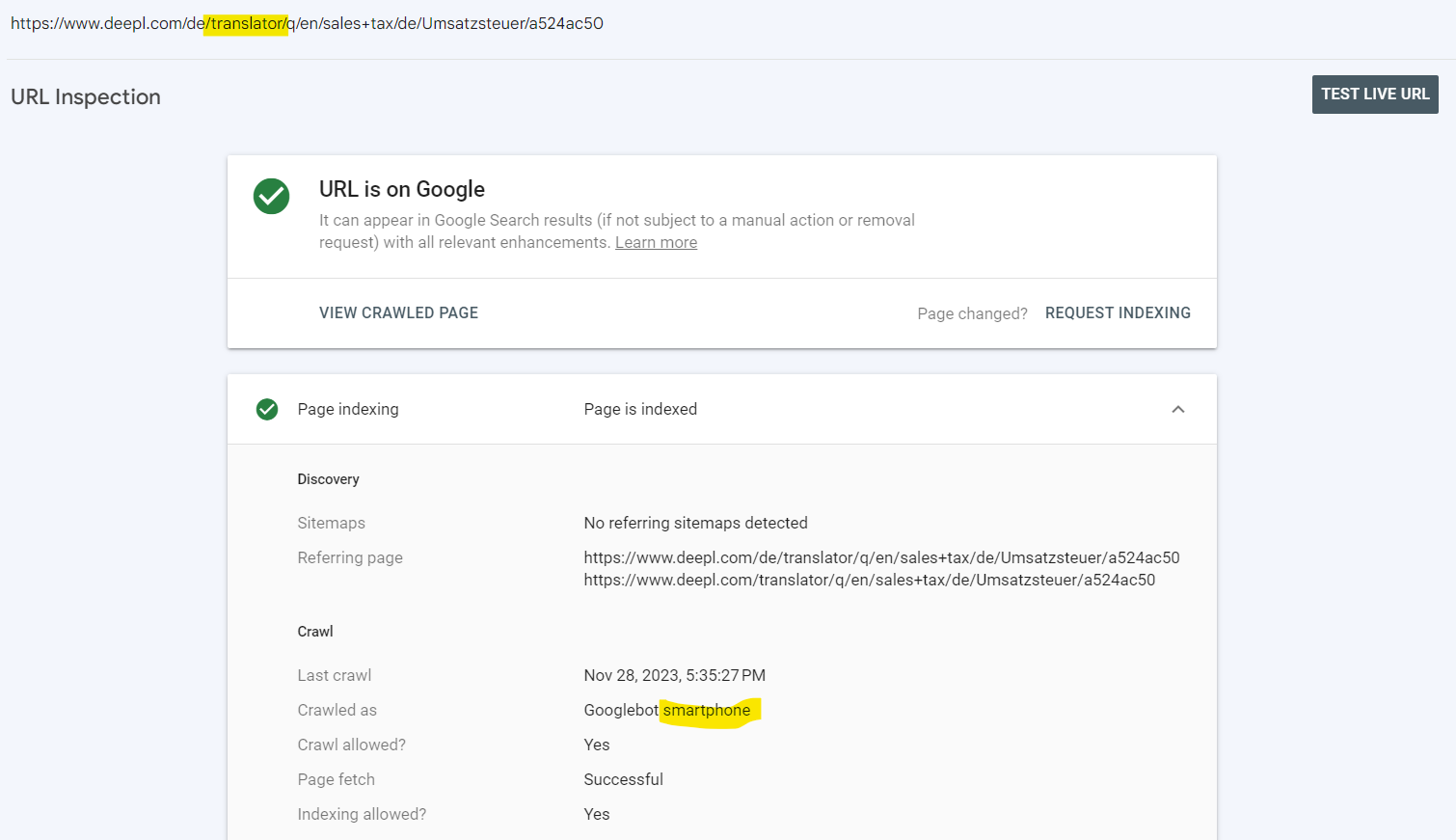
At the time of writing this, our domain still serves mobile pages via a separate URL (anyone else getting nostalgic here?) - which means Googlebot smartphone receives a redirect if they crawl the URL dedicated to large viewports. Except they won’t tell you that in the URL inspection tool.
Let’s take the following URL as an example: This URL is designed for large viewports with a JS redirect to its mobile equivalent /translator-mobile/$restoftheurl.
Page inspection tells the URL has last been successfully crawled and rendered by Googlebot smartphone:
If you ask GSC to fetch and render the page aka “Live test URL”, it is going to fetch it with an equivalent of Googlebot smartphone. Let’s see what happens if we press this button…
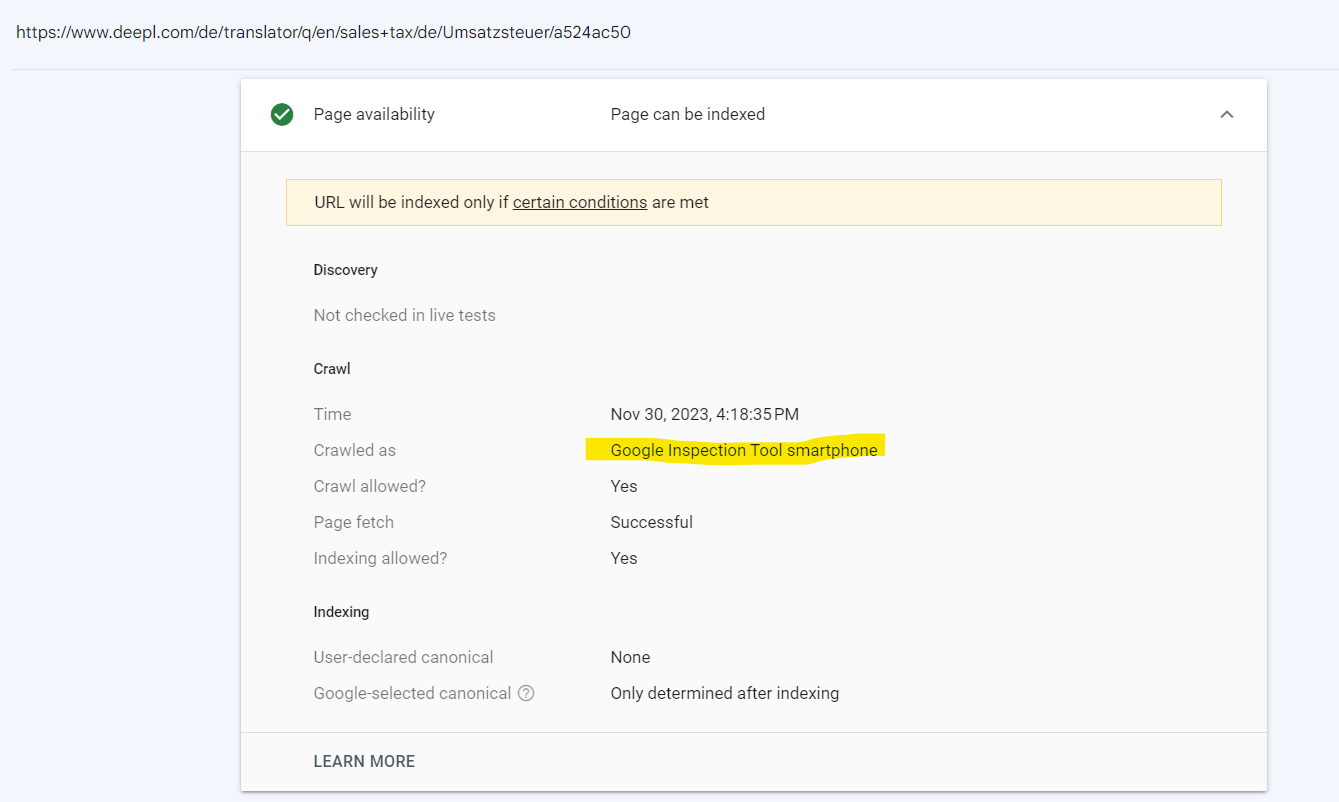
Upon checking what response Google Inspection Tool smartphone received, we should expect a redirect. What we find instead is that it received the HTTP response 200 and could render the page just fine — the mobile page. It does not show us the intermediate step of the redirect.
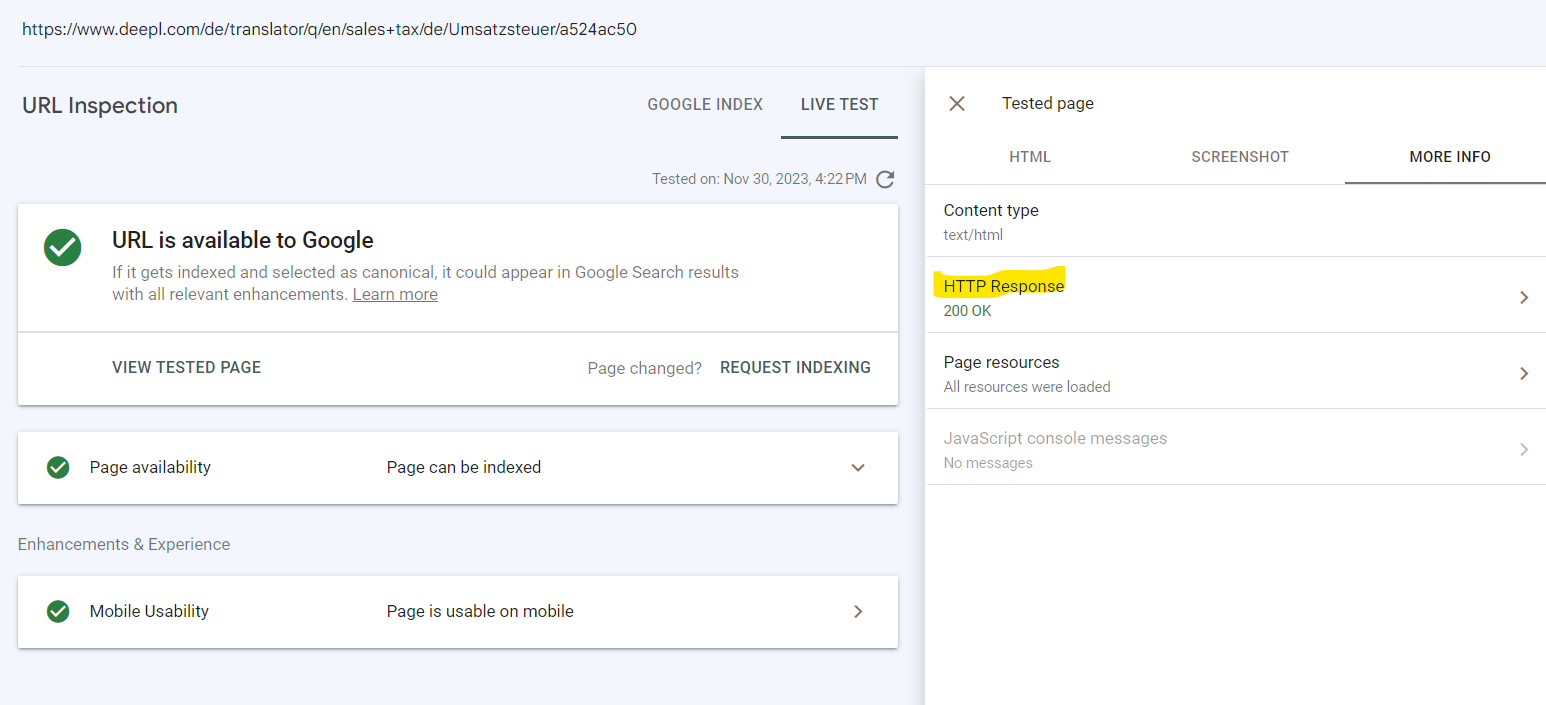
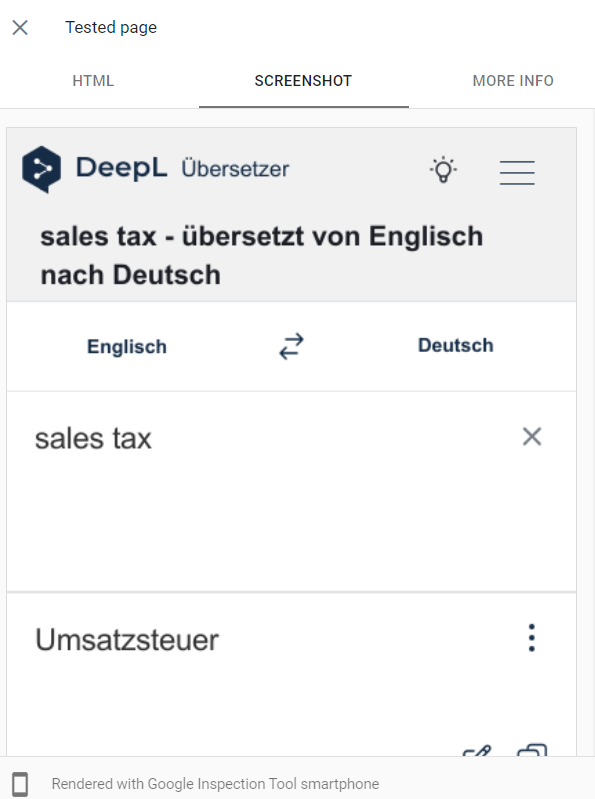
As we are writing this article, Google have included a note about the live test handling redirects in their documentation (who stays up to date with all their changes in their documentation, though?). It does make you wonder how this is making sense, however:
“The test first follows any redirects implemented by the page, then tests the page. However, the test does not indicate that it has followed a redirect, nor will it display the final URL that was tested.”
At this point, I’m afraid we might be expected to just keep track of all the discrepancies and ambiguities by ourselves.
The same happens if you use their soon-to-be-deprecated Mobile-Friendly Test tool. You used to be able to query the Mobile-Friendly Test via Search Console API but this part of the API is also going to be deprecated. This might cause a migraine even for seasoned SEOs, as they might suspect something is wrong with the redirect settings. Yet when we test in a browser (at the time of testing this: Chrome Version 119.0.6045.160 (Official Build) (64-bit), fresh incognito window, user agent: Googlebot smartphone, screen set to Pixel 7), we can see that there has been a redirect (even though it was not via a 301 or other HTTP status code):
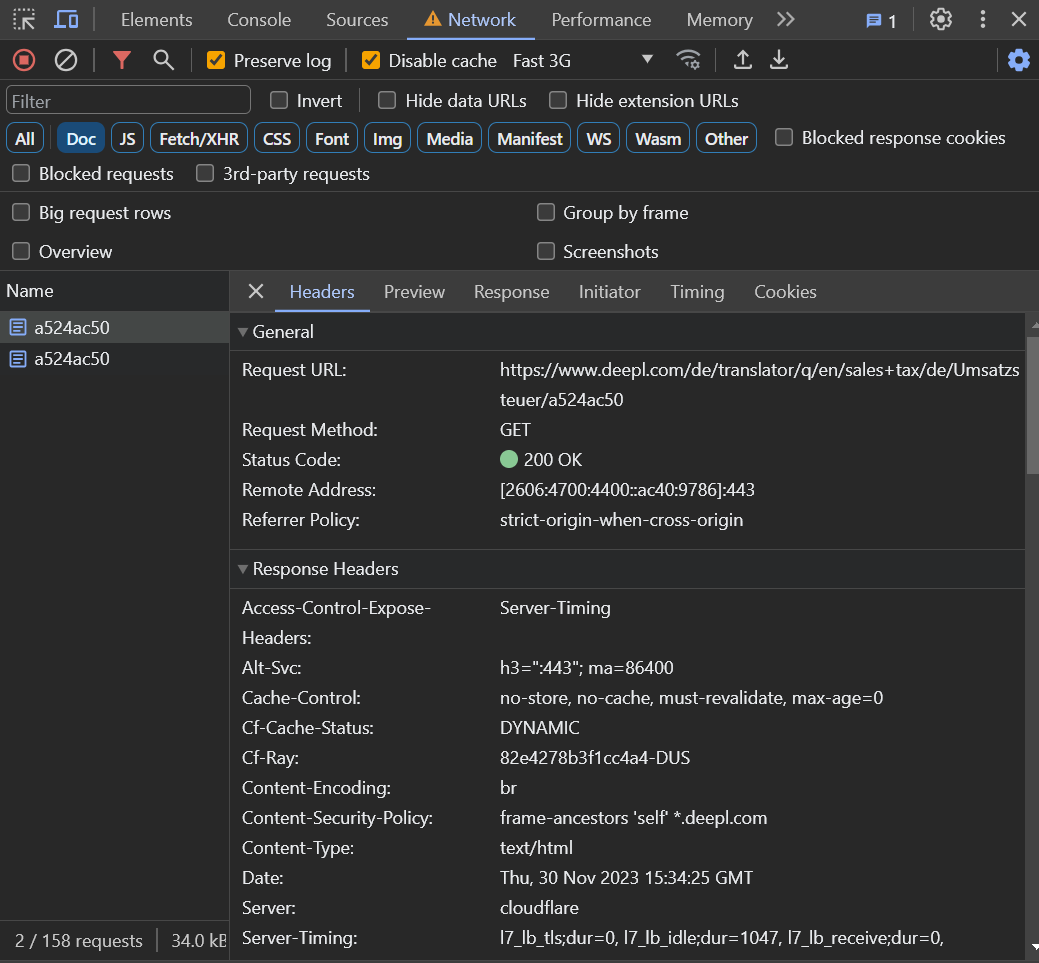
It is even easier to see if you use a plugin, such as Redirect Path by Ayima:

This can be especially upsetting when you’re involved with a larger project - such as a domain migration - you plan everything according to Google’s documentation and best practices, and still end up losing traffic and having to deal with inconclusive Search Console reports.
“Everything here looks as it should - Google “selected” our new domain as the canonical for our old homepage (great). We go to check out our homepage for our new domain and we end up finding that Google has labelled it as a “Duplicate, Google chose different canonical than user” and we are provided with a N/A entry for Google-selected canonical.“
This comment from a user reaching out to Search Console Help is from 2019. URL inspection has had inconclusive moments for years - it is about time Google fixed it.
Managing access and restrictions in a large company, and/or for a large number of properties is one of my most hated administrative jobs - there is no way to add or remove a number of users in bulk, or to change their restrictions. You have to do it one by one, property by property. GSC makes me want to scream into the void any time we have a new joiner on the team, or someone needs their access removed.
Myriam Jessier described a spooky phenomenon in access management:
“I created a personal Google account. Added a few GSC from clients. Switched to a paid google workspace account. This means my previous GSC access for accounts got transformed into a name.temp@domain.com. No way to access the accounts. No way to remove myself. Just haunted by alert emails for 7 years now.”
Virtually all reports in Search Console have data delays. If you rely on those reports to see if a recent bug fix helped recover your traffic, indexability, or crawlability, GSC makes you wait quite a while:
The 28 day monitoring session of the Core Web Vitals report in GSC can make it tricky to understand when that window started or ended (although you can start it by yourself for revalidation), or map it against other reports in GSC (e.g. after a deployment that you’d expect to change how Google renders your pages) which have their own evaluation windows. And since this report too, is sampled - it might not pick the same URLs in that sample as you see in other reports - therefore you might find it difficult to run comparisons between reports.
Yet another thing that is not an error, but I find mildly annoying, is that in order to circumvent limitations for data retrieval via the API, or get more data when it is all sampled, you will need to have a URL structure that allows you to set up multiple properties in Search Console. If you start out with a new client, or if you handle a large domain, you might not have the luxury of renaming all URLs or be able to afford the risk of setting a large amount of redirects, just to bring the domain into a structure that allows you to set up multiple properties.
Data is only going to be recorded and displayed from the day you set these properties up - which means if you set them up now, you won’t see any data from the past, either, although Google likely do have that data available.
This is where Bing Webmaster Tools shine: they cluster URL directories automatically for you (but still require you to have them in the first place!).

If you need data now, and cannot get new properties verified in Search Console fast enough, you need to write your own regex - especially if you intend to compare different content types that might not be filtered cleanly enough by including or excluding specific directories or IDs in the URLs.
If you are anything like me, you might find writing regex from scratch just as easy as wrangling a greased-up squid. Just don’t even try to use ChatGPT for this job - spare yourself some time. It’s likely not going to work (or might confuse you even more), as ChatGPT might not be aware of the flavour of regex (for GSC it’s the RE2 syntax), and certainly is not aware that even when you filter by regex in GSC, there are pre-filters such as “exclude/include”. In my tests, it was not even able to debug its own creation when given the correct answer for comparison. (Please note: ChatGPT is, like some similar solutions, being updated, and therefore might do a better job eventually.)
If you need good working examples for regex that might not only help you in Search Console - check out Myriam Jessier’s article about Regular Expressions for SEO.
Does anyone still remember the fabulous Structured Data Testing Tool (SDTT)? Google replaced it with the Rich Results Test in July 2020. After announcing the SDTT’s deprecation, the community’s feedback has been so strong that they decided to keep it but migrate it elsewhere, and to no longer have it show a URL’s eligibility for Google’s Rich Results. Since then, it is rarely mentioned anywhere, unless you really look for it.
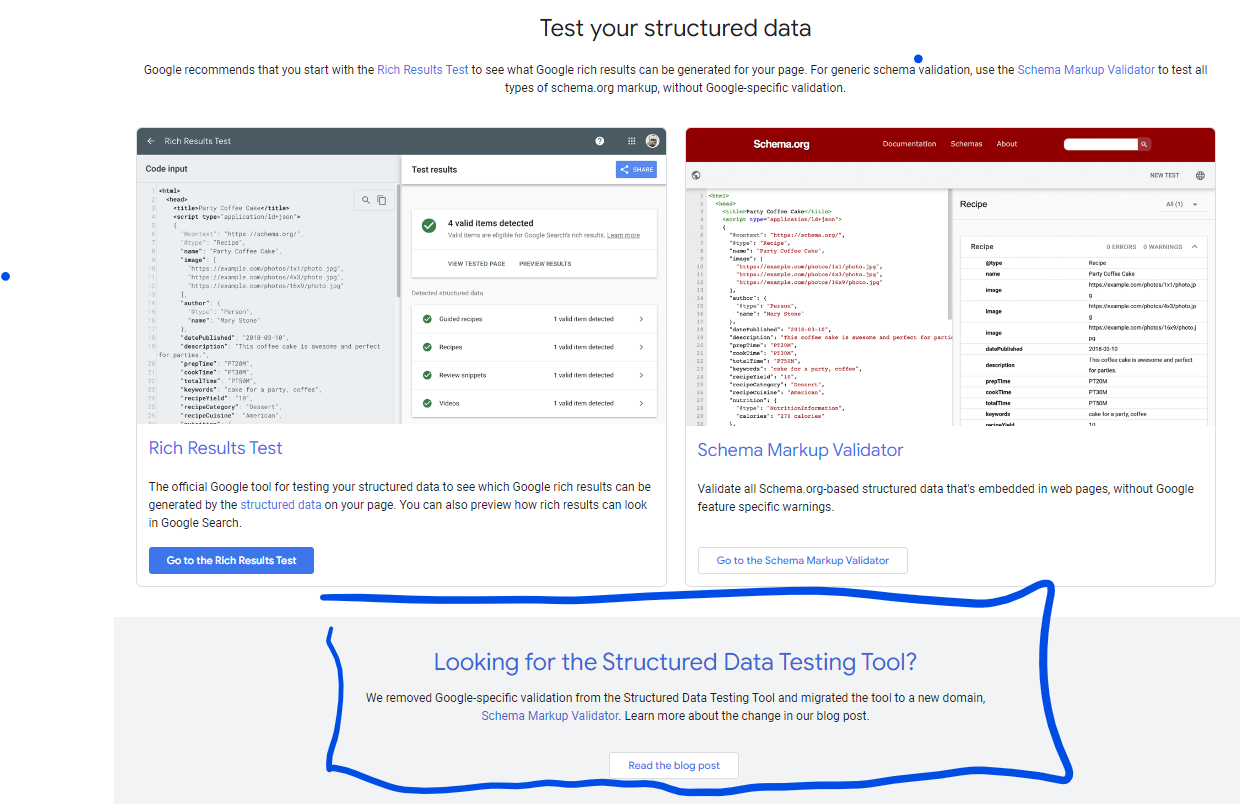
Other tools that were discontinued, but helpful:
URL Parameter Tool, discontinued as of April 2022
International Targeting Report (hreflangs), discontinued as of September 2022
Good Page Experience filter in GSC, discontinued as of November 2023
Robots.txt Tester, deprecated in December 2023
Mobile Usability Report, Mobile-Friendly Test tool and API, deprecated since December 2023
Crawl Rate Limiter, deprecated since January 2024

Strictly speaking, these aren’t Search Console tools, but they were previously useful:
Sitemap ping endpoint, discontinued since December 2023
Cache Link, deprecated since January 2024
While Google often launch a substitute for these tools, their functionality is often not the same:
The newly introduced robots.txt Report, for instance, does not allow you to test changes to your robots.txt anymore; Google’s documentation now even links to Google Search where they reference cases where you may want to validate your robots.txt file.
The International Targeting Report gave us really helpful insights into hreflang errors, but SEOs now have to resort to external tools and other testing methods (as they won’t see potential Google-specific issues with hreflang in Search Console anymore).
Whenever Search Console finds a new error in any of your properties, you receive an error notification email. They cluster all errors into error classes, which you can find in the emails (quite practical, as you could use these to set filters for them if you wanted to).
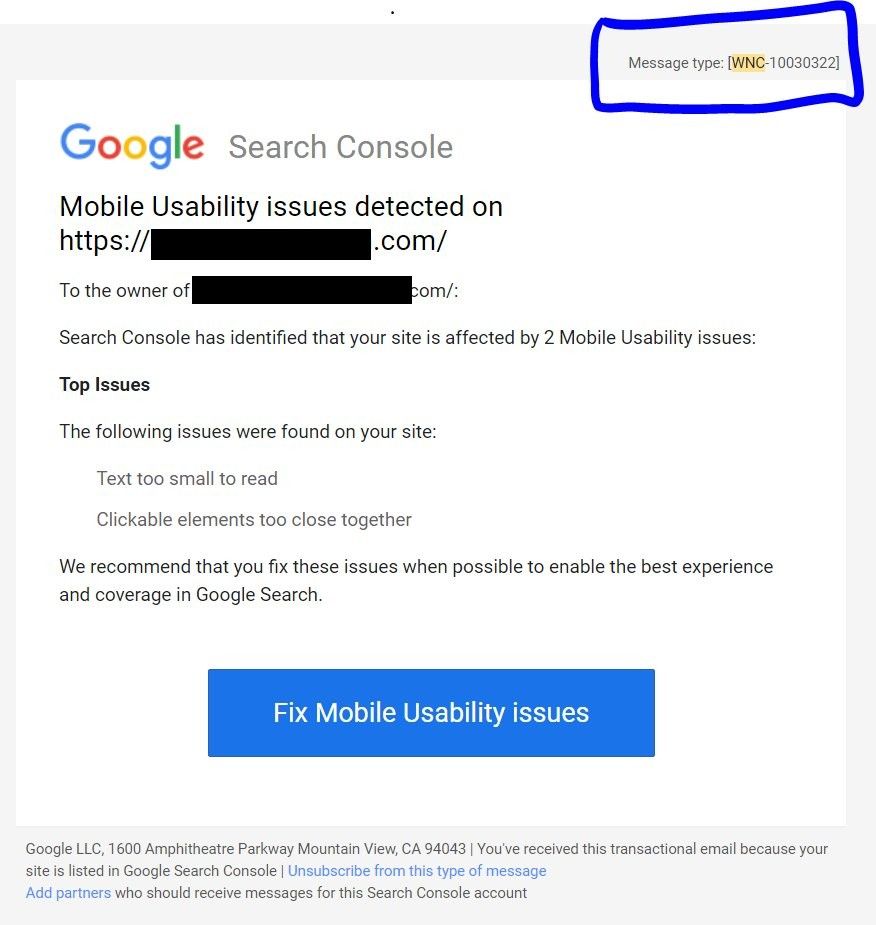
However: These error class notifications do not contain sufficient detail. The email might let you know that there is an indexation error - but you won't know exactly what type of error. Google have at least 13 potential errors in this class alone. Their notification won't tell you if it's just a Discovered - not indexed or a Server error - 5xx - which makes it much harder to prioritise when you need to dig deeper or use these as a fallback monitoring.
Also, if they make any changes to classifications or labels, these changes might not be used consistently throughout the Search Console ecosystem. If you are lucky, they inform us somewhere in their documentation:
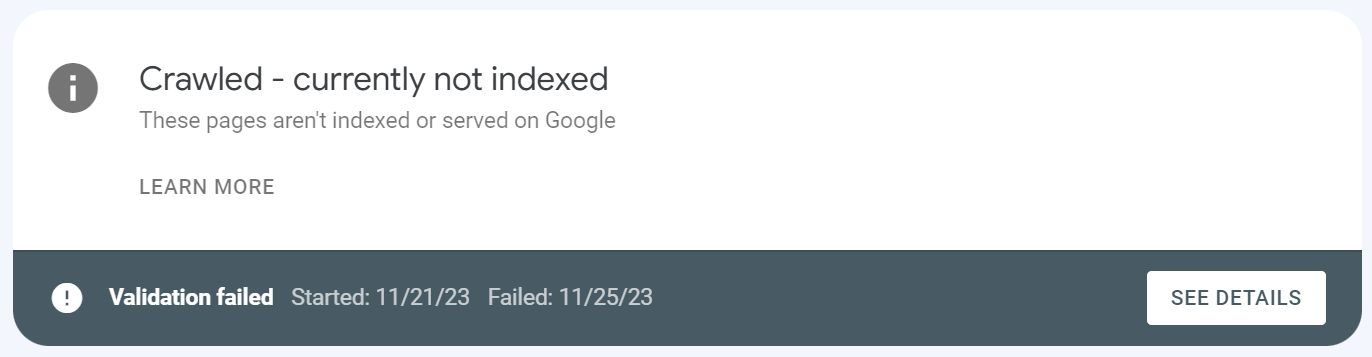
The amount of time it takes to wait for validation in GSC would make watching seagrass grow seem expeditious. If you’ve just fixed an important bug, tested thoroughly and want to make sure you really have found and solved the cause of it - you cannot rely on revalidation, and you won't know if it has been solved before weeks have passed. How many weeks? Nobody knows!
Even more painful: If you fix errors that affect a bunch of URLs in one of the error reports in GSC and ask for those to be revalidated, it will also test URLs in the same error class that have not been fixed, and validation will terminate early. GSC will tell you that validation stopped but it won’t tell you where, why, or which URLs it had successfully crawled and removed from the error report before it stopped validating.
And since any exports will only contain a sample of maximum 1,000 URLs, it might not be worth the effort to map the URLs you fixed against GSC exports anyway.
Sometimes, understanding if Google had issues crawling your website at scale might give you valuable insights. For example:
It can help make sense of errors you might have observed in other GSC reports - but the Crawl Stats have their flaws, too:
While the Performance Report in GSC allows you to go back 16 months, Crawl Stats only show for the last 90 days. This can be annoying if you wanted to compare crawl behaviour over a longer period of time, or with movements in your website performance.
Crawl Stats are, just as elsewhere in Search Console, sampled - and when you export the limited amount of data, you don’t get the response times or crawl attempts per URL. The Crawl Stats export contains two tabs. The first listing average response times for all crawl requests per date for the last 90 days:
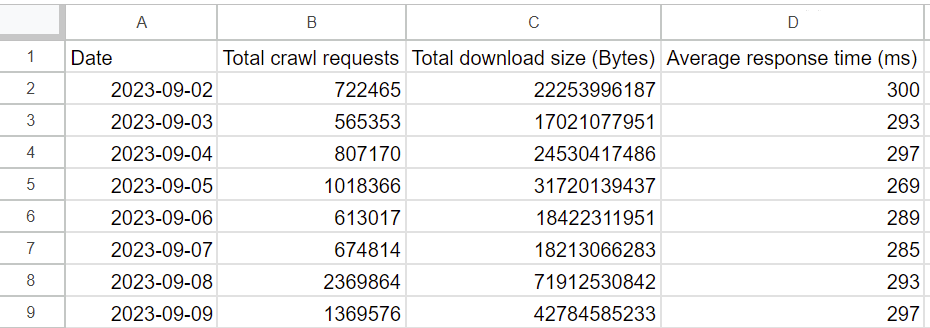
The second tab gives you a limited set of 1,000 URLs, date and time when they were crawled, and the status code they responded with - but not their response time.

Can you export response times per URL, at least? Nope.
Can you request Crawl Stats via Search Console API? Not that I know.
Can we at least get more data by setting up different properties, as we might do with all the other reports in GSC? Unfortunately, Google will only report root-level data - which means sampled data for the domain, not per directory. If you access Crawl Stats via any of your smaller properties such as domain.com/en/, you will be referred back to the main property domain.com and only see sampled data for the whole domain.

Lastly, what you see in the Crawl Stats is not the full picture; if you compare your access logs (after a careful reverse DNS lookup to verify requests by The Real Googlebot™) to your Crawl Stats, you will see a difference. Google seems to have an issue with showing all the requests they may have made.

Ever had your boss or your client compare data in GSC with their own traffic reports and ask you to explain the inevitable discrepancies? You know the pain.
GSC only shows you sampled data - meaning they select a set of data they deem representative, and show it for your property. Even if your website does not consist of thousands of pages, you might have to divide it into a few smaller properties and verify these in Search Console separately to get a more complete picture. That way you get more data, even if it’s still sampled. (This also means that your future holds the administrative debt of handling user access manually for each of these properties, as detailed in Exhibit 3 above).
Now this is probably the biggest issue. Since it has been reported elsewhere, I am only going to summarise the issue for you and link out to studies conducted by others for your reference:
If you fetch or export data from the GSC user interface, you are not going to see the same picture as the data you might pull into your own data warehouse via the GSC API. The same happens if you are using any third party tools which aggregate your GSC data with other data, as they pull the data via their API, too.
This can make it much harder for SEOs to request budget to either pull data via the API into your own solution, or join it with and subscribe to a third party tool, as a lot of managers might not trust the data.
Some providers such as Schema App created specific guides to explain the discrepancies in data shown.
In theory, the clicks reported in GSC should be roughly equivalent with the organic traffic for any access via Google Search, minus the percentage of users who might disable tracking and cookie loss, right?
There are multiple reasons why clicks might be underreported. As this has been discussed by others better than I can cover in this article, I’m going to keep this brief:
GSC reports clicks, while Google Analytics (GA) tracks sessions. This typically leads to a difference between the reports. If you’re interested in the details, read Michael King’s explanation.
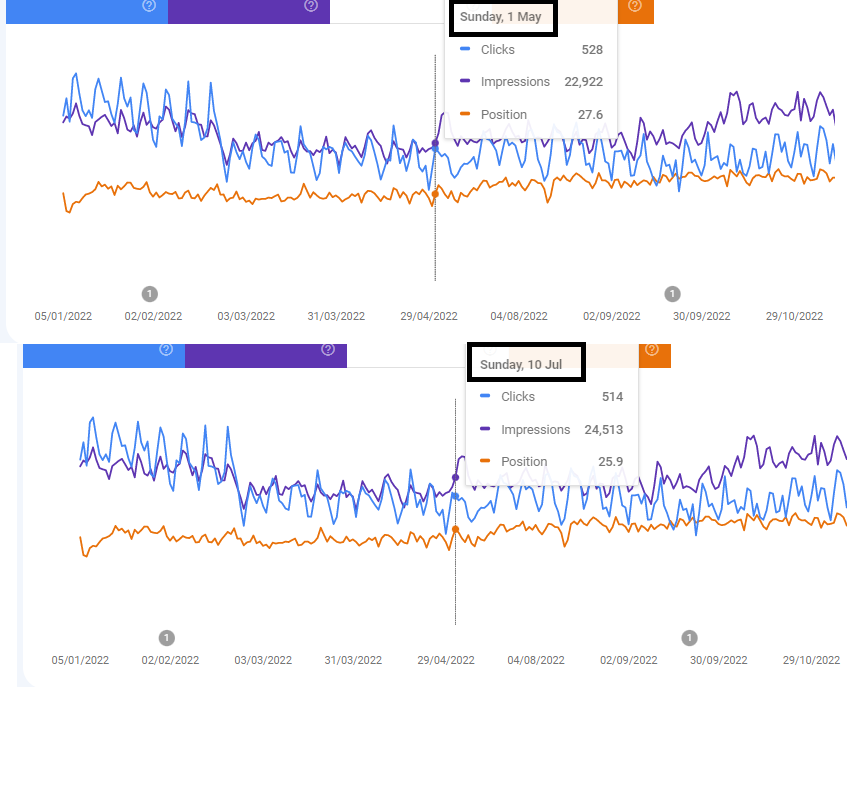
Daniel Foley Carter provided us with some screenshots on LinkedIn:
“GSC has had lots of bugs including large chunks of missing data. They're changing functionality without fixing what they already have. Very frustrating.”
The same can happen in any report in Search Console, be it the Crawl Stats as shown earlier, or the Page Indexing report. One of these changes in July 2023 might have made it seem the number of errors with page indexing were jumping up. This surely must have caused some headaches.
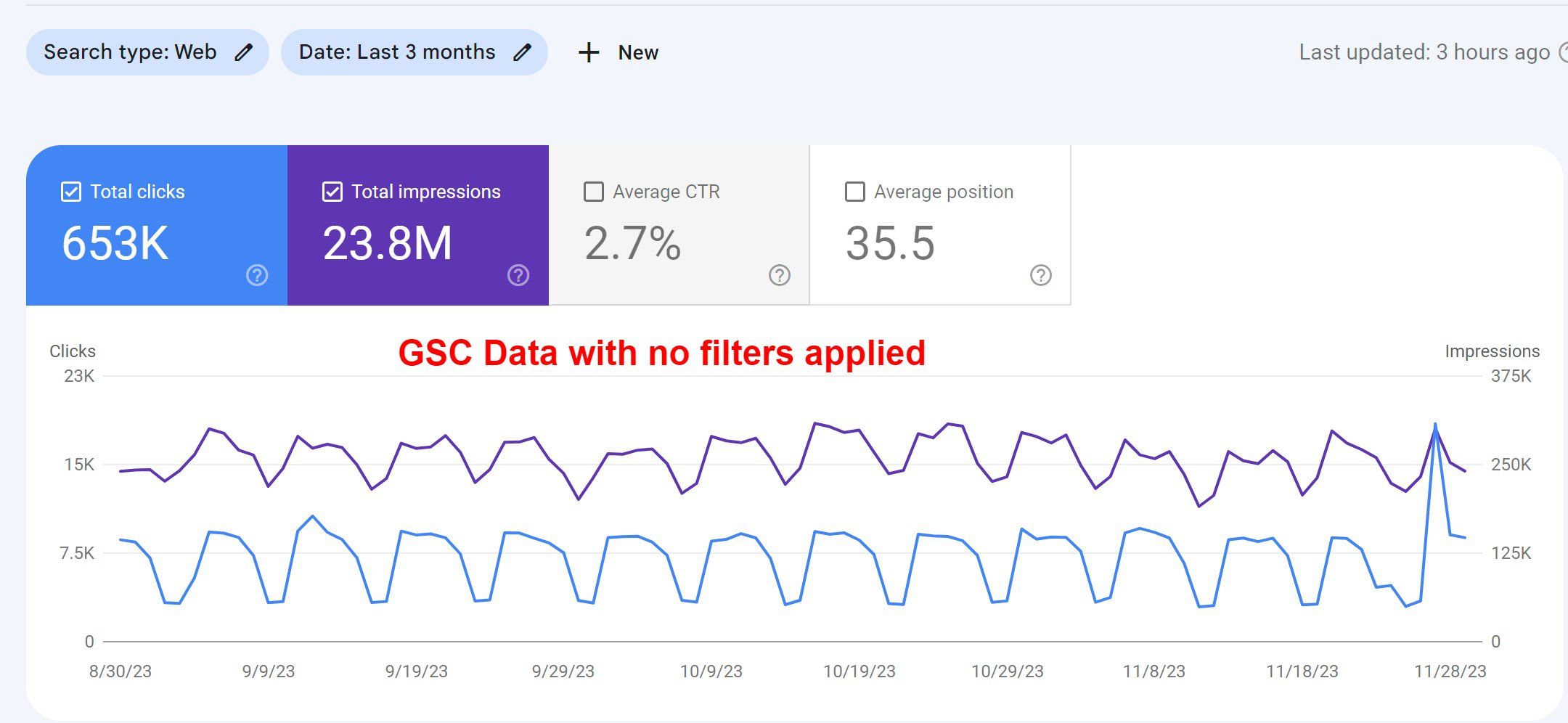
Using GSC as your main source for keyword research? Ahrefs and blinkseo have conducted studies to show that a high percentage of queries are not shown in any report. According to Google, this is caused by at least two main factors:
As a result, you may see differences between different reports as you drill deeper within the same property (or multiple properties of the same domain). Max Peters shared his observations and examples for query anonymisation on Twitter/X:
“I think most peeps know about hiding of "anonymous queries", but it really messes with data reporting & is hard to explain to stakeholders.”
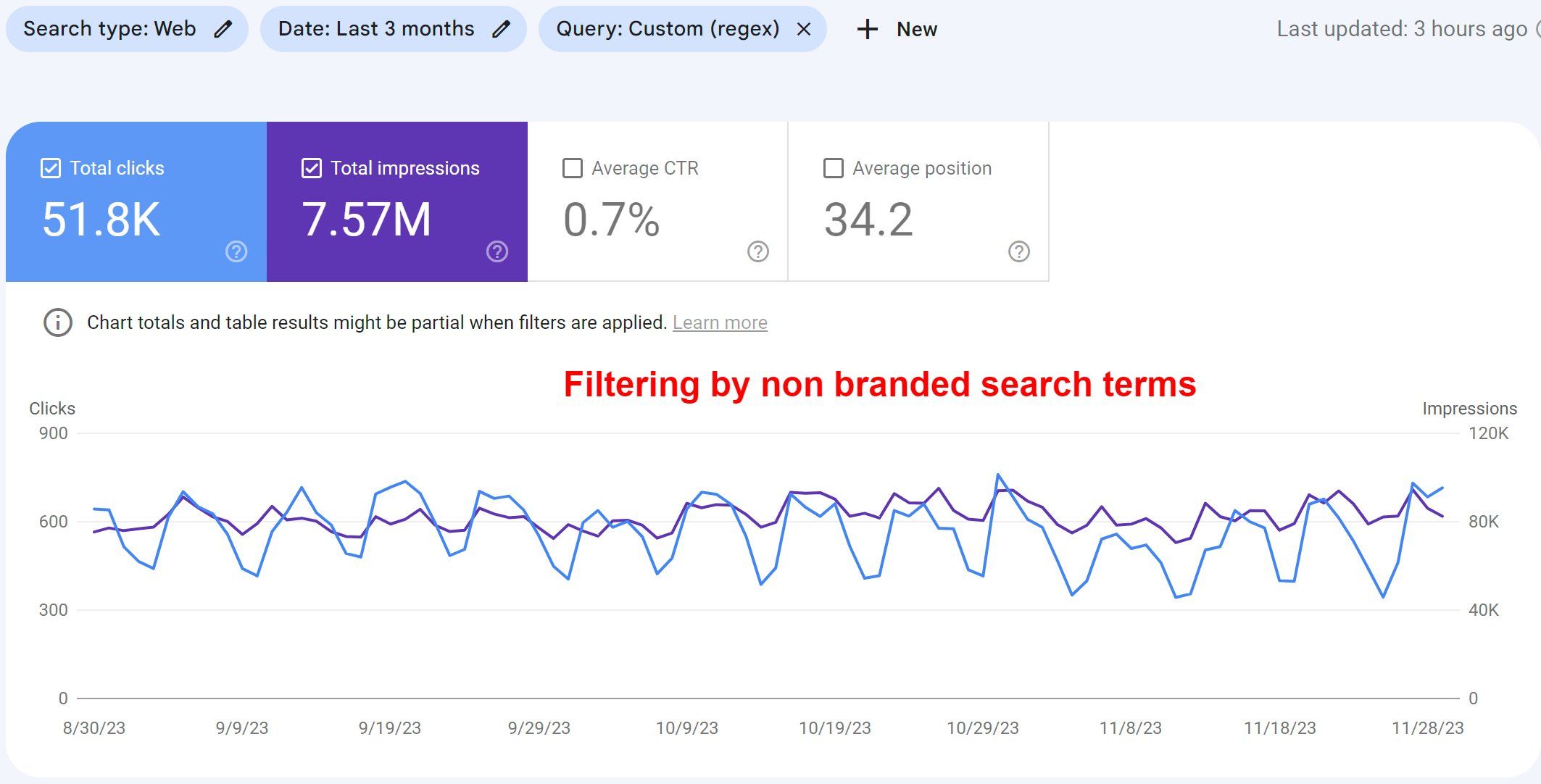
It is worth checking out the studies we linked above in order to gain a deeper understanding of the scale at which this stuff happens, and form an opinion about what this means to you. Be sure to also check out Google’s documentation about data discrepancies.
If your website offers enough content, and has a lot of traffic, introducing or improving your internal search can add really valuable insights to complement those from GSC.
All these issues lead to frustration for SEOs, and it’s not uncommon for people to trust other solutions more than Google’s own tools. Also, have you ever tried to onboard an editorial team to Search Console to monitor the performance of their content without your help? Usability does not seem to have played a big role in its design.
I’d strongly suggest that you build an infrastructure that makes up for what GSC is lacking, and helps you make sense of any confusing signals you might run into.
If you do have the budget for larger SEO enterprise suites which might include regular crawling and checking of your site’s health, use tools such as Testomato or LittleWarden. You might even be able to test a small sample of URLs for free, or for very little money.
Tip: Check one URL per page template for errors to save budget.
Screaming Frog or Sitebulb might be the best solution to get you almost anywhere (you can even test automation and monitoring, if you have the technical expertise!)
Use Lighthouse in your browser, or web-based tools provided by Onely.com. You can find more alternatives in Olga Zarr’s guide on how to render as Google.
It’s not all bad. Search Console can help you troubleshoot when you lack the means to set up a thorough infrastructure, or even act as a fallback tool for monitoring and quality assurance. (Did you know you can filter GSC alerts for error classes, so you only see the most urgent ones that need your attention?)
There are amazing tutorials out there showing you what you can do with Search Console; and considering that it is free, and provided by the search engine that might account for the majority of your organic traffic - you should aim to understand as much about it as you can.
You just shouldn’t take it as your single source of truth.
Add similar tools by other search engines to the mix. Bing Webmaster Tools however can give you different insights into your domain. And don’t fret if you see some discrepancies: It’s not you, it’s GSC.
It’s likely that you are going to run into errors that really do need to be fixed.
The first rule is: Do not panic! There are excellent guides out there to walk you through any issue and what you can do about them, such as this comprehensive guide for any kind of GSC error by Tory Gray and Begüm Kaya.
Google Search Console is still a valuable tool.
Point is, Google have had ample feedback from SEOs about improving this tool. One might think that if you've been around as long as Google, basic things like accurate HTTP status codes wouldn't baffle you anymore. Alas.
And without many of those once-helpful tools we took for granted, it feels like we're left clambering in the dark.
But we forge on with stubborn optimism! We shall complement GSC's glitchy matrix with other tools, and continue querying this temperamental beast called Search Console. We endure because we must. Such is the life of an SEO. Le sigh.
My personal opinion after 15 years in the industry?
If a company holds a monopoly over a “natural” traffic source such as Google with organic traffic in most countries in the world, they also carry a lot of responsibility. They should provide website owners with a reliable, well-documented tool to manage their sites and the most common errors. Otherwise, we essentially exclude any smaller business, especially in economically struggling countries, who might not have the budget to build their own infrastructure or use third party tools.
If you would like to dive deeper into this topic, here are a few additional resources about Search Console, its potential, and its limitations:

Gianna Brachetti-Truskawa - Senior Product Manager SEO, DeepL S.E.
Multilingual technical international SEO expert with over a decade of experience and a passion for intricate tech setups, currently breaking down language barriers at DeepL.com. Former tech translator who found their true calling in the deep sea of search!
We pay our authors, speakers & team to bring you helpful content like this.
We aim to always keep our content and community free and accessible.
If you've found value in WTS, please consider supporting us through our Buy Me a Coffee initiative.
