🎤 Next up: WTSFest Berlin
⌛ Limited early pricing tickets live for Philadelphia, & Melbourne
🎥 London 2025 on-demand recordings & 2026 tickets
🎤 Next up: WTSFest Berlin
⌛ Limited early pricing tickets live for Philadelphia, & Melbourne
🎥 London 2025 on-demand recordings & 2026 tickets

Author: Michelle Race
Last updated: 24/01/2024

If you’ve ever had to review a website for a technical audit, content or optimisation review, it’s likely that you’ve used a website crawler to perform this task. A crawler will crawl your website following all links from the homepage and report back on the URLs, page elements and issues found. Out of the box, crawlers are designed to report on these common aspects to suit a wide range of websites and industries. So you would expect to see page titles, descriptions, H1s, status codes, and indexation status as standard.
While these standard reports are extremely useful information to have, you may find yourself wishing that your crawler reported on more specific parts of your website. Each website is unique and there are often distinct metrics and areas to cover based on your role or SEO specialty whether you are a tech SEO, data analyst or content writer.
Luckily, most crawlers have a useful feature which allows you to pull additional information from web pages during a crawl and this is commonly known as a custom extraction. The beauty of custom extractions is that you can tailor them to extract the data that is valuable to you and your team, and use them alongside your normal crawl data.
In this article, I’ll share some custom extraction ideas, highlight the benefits these can bring, and show how these custom extracts can help you level up your SEO reporting and analysis.
A custom extraction is a way to scrape or extract specific data from a website at scale. The extractions you implement may be useful for just a single crawl or could be ongoing elements that you wish to keep track of.
Here are some use cases for custom extractions:
The most common reason to extract particular elements or sections on the pages you’re crawling is so the extraction data can be reviewed and used for analysis.
Examples:
You can use custom extractions to check that an element exists on the pages being crawled which is useful for auditing purposes.
Examples:
Sometimes there can be particular errors on your website that you may want to track via an extraction. This is especially useful if those URLs don’t return a 4xx status code which would flag as a standard error page in a crawler.
Examples:
You can also use custom extractions to save time and resources.
Examples:
The most common way to set up customer extractions is to use Regex, XPath or CSS Selectors, however, crawlers vary, so it’s best to check the documentation of whichever tool you’ll be using. I highly recommend looking at some online training courses and guides (e.g Regex, XPath) to help you get up to speed with the syntax and methods.
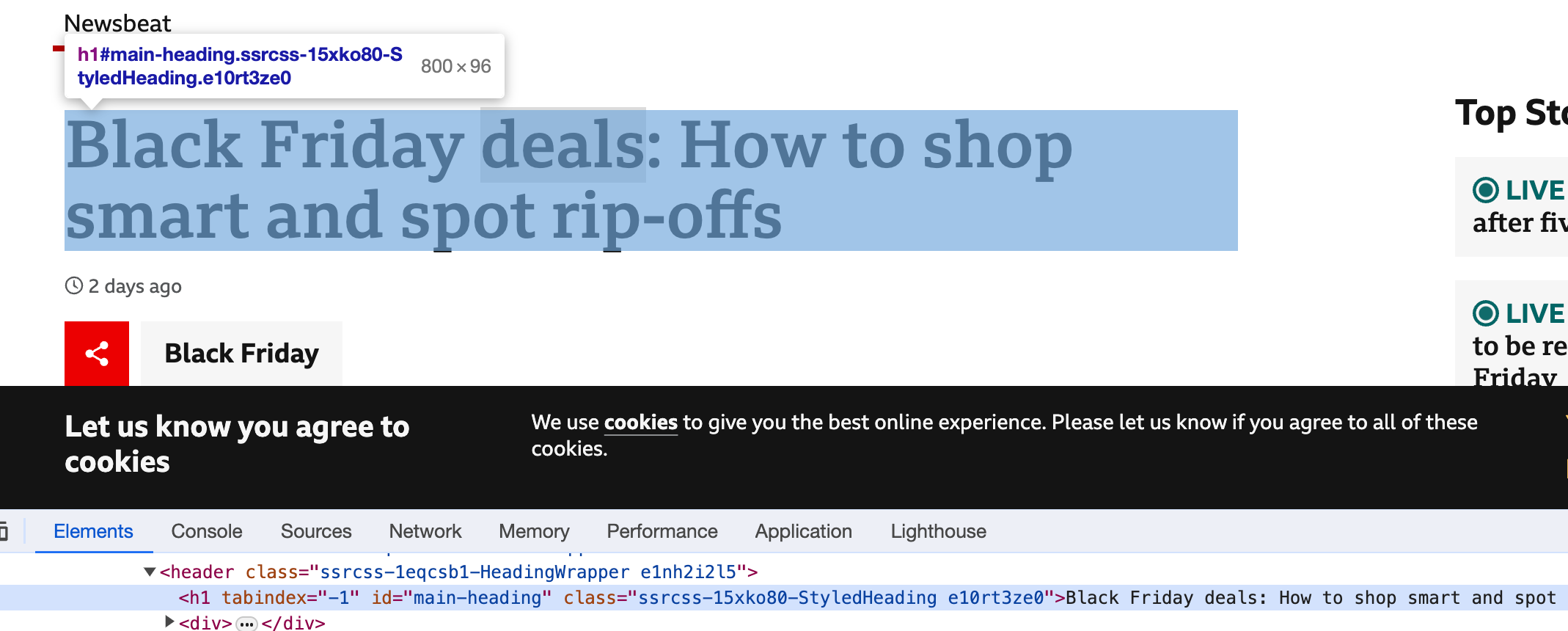
Once you know what you want to extract, it’s time to look at the code and identify patterns and unique parts that relate to it. If you are using Chrome, right click on the page element, select ‘Inspect’ and it will show you the HTML.
Some elements like schema are not visible on the page but only seen in the HTML. For example, if you wanted to capture datePublished schema from your blog posts using regex and the schema looked like this within the HTML: "datePublished":"2022-09-26T22:18:45+00:00", then your Regex could be as simple as this: "datePublished":"(.*?)" (the part between the brackets is saying to capture everything within those quotation marks as the custom extraction).
If you wish to use XPath or Selectors but don’t know where to start, you can use Chrome DevTools to check the elements that you need.
Go to the page, right click and choose ‘Inspect Element’ which will open up the Elements view. Select the element you want to see the XPath for, right click on it and select “Copy”, this will open up a set of options which can help you generate what you need. You will often still need to make this more specific but it can set you on the right path.
There are free online tools you can use to help build your custom extractions such as RegExr for Regex.
If you are using XPath or Selectors and quickly want to test on a per page basis, you can use Chrome DevTools. If you go to the Elements view (right click and select Inspect) and then Ctrl + F to bring up the search bar, you can then paste your XPath/Selectors. Unfortunately you can’t use this to test Regex but there are additional Chrome plugins that can help with this.
If you’re on a page that should match, it will highlight the element found when your XPath or Selector is pasted in. If you match more results than expected, it could be a sign that your extraction is too broad and needs to be refined.

I find that the best way to test your custom extraction is working correctly is to identify some URLs that should match, and some URLs that shouldn’t, based on what you are testing. You should then crawl just those URLs and check the output. The reason to test URLs that shouldn’t match is that if you are setting up an extraction to track a certain template such as a PDP, if you get matches for all URLs you’ll know that it’s not a unique enough identifier. Doing this testing will prevent problems later.
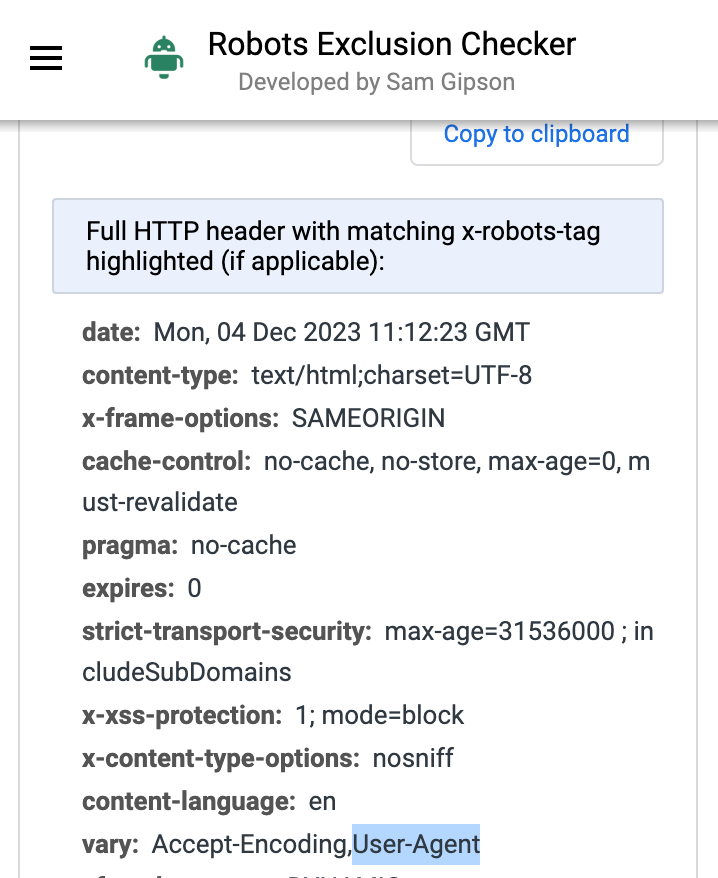
Another thing to be aware of is that some websites may be using a dynamic serving method where different HTML is provided depending on the user-agent. If a website contains the vary : User-Agent HTTP header, different HTML could be served for a mobile versus desktop user-agent on the same URL. If this is the case, make sure that you are getting the extraction for the version you are crawling as the class name or identifier could change. If your website is using dynamic serving and you are crawling using a smartphone user-agent make sure that the extraction is based on the mobile version. You can check this by using a plugin or online tool that shows HTTP headers. The Robots Exclusion Checker by Sam Gibson is a fantastic Chrome Plugin that as part of its many SEO uses shows HTTP headers.
It can take a few tests to ensure that everything works as expected but it will be worth it in the long run.
Not sure where to start? Here are some custom extraction ideas split out by industry. These examples have been invaluable to me in the past when creating audits and helping to support business decisions.
Extract the text that appears for stock status - you could choose just to focus on out of stock or also add in stock and discontinued products. Use the relevant sold out text e.g ‘Sold Out’ or ‘Out of Stock’, any unique identifiers or extract the relevant availability field in product schema e.g. "availability":"http://schema.org/OutOfStock"
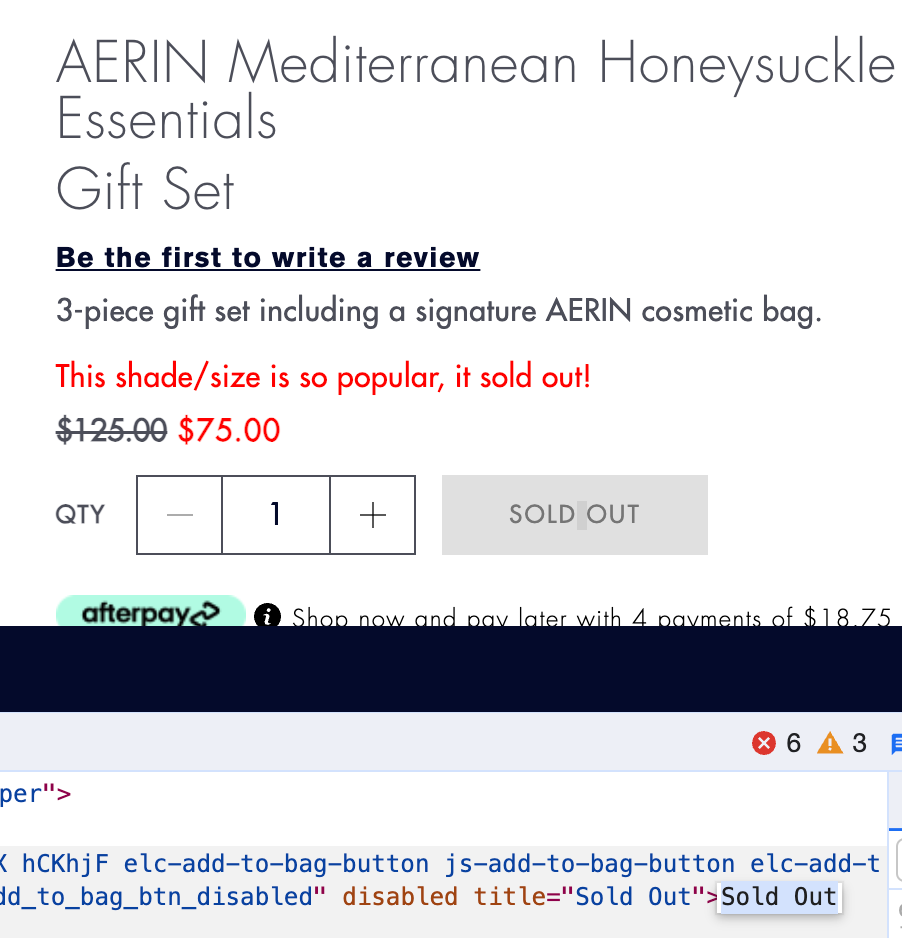
Tip: you may need to add extra checks to make sure the extraction only pulls out PDPs and not PLPs if you are extracting just the text as it could also be added in the listings.
Why is this useful?
It allows you to:
Extract the text that appears if a listing page is empty e.g ‘no products found’
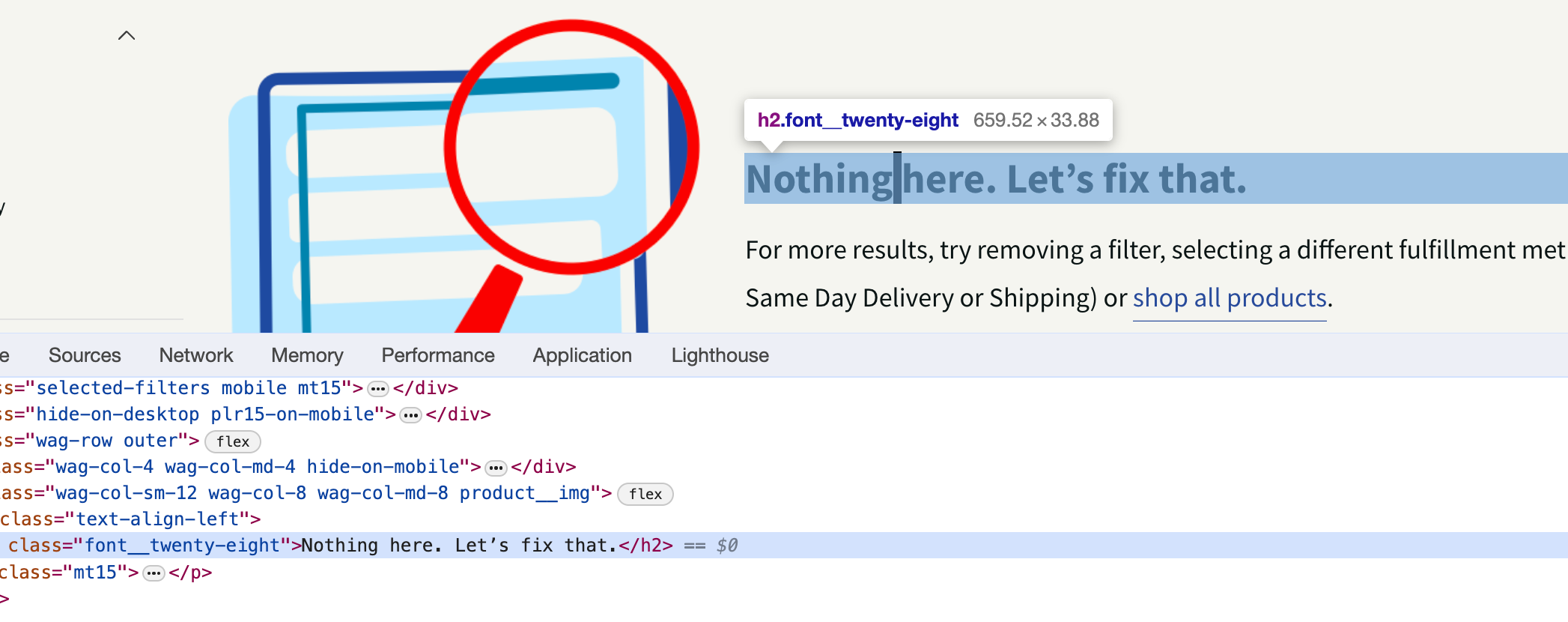
Tip: if you are just adding in the text as your extraction make sure that the casing used exactly matches what is on the page.
Why is this useful?
It allows you to:
If there is a count somewhere on the page such as ‘x’ items surrounded by a div with a specific class you can extract that:
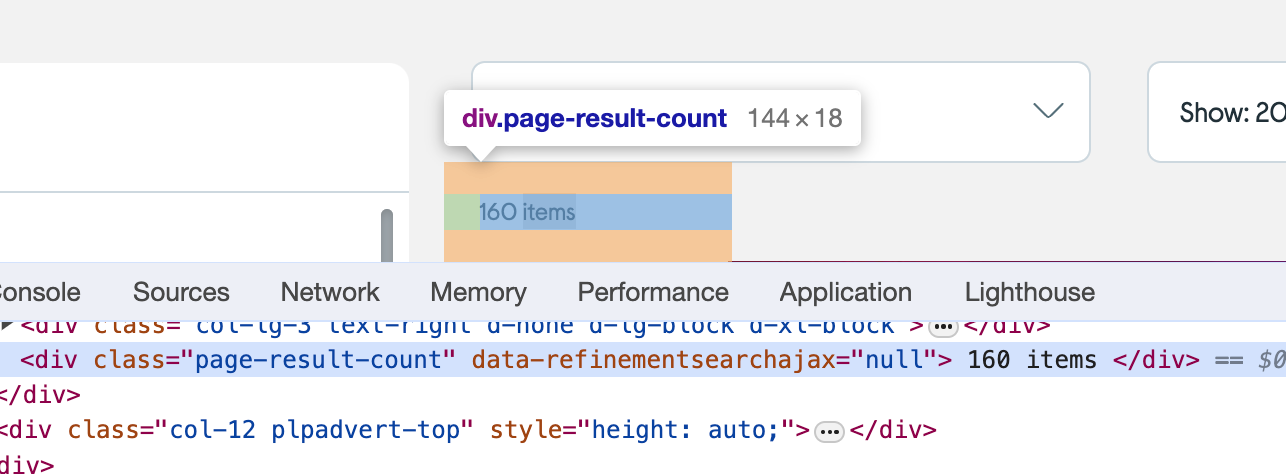
Or if the count isn’t within its own tag like <p>Showing 10 of 200</p>, your regex used could be this : <p>Showing \d+ of (\d+)<\/p>.
Why is this useful?
It allows you to:
Find the class/id of the div surrounding the unique content on the page:
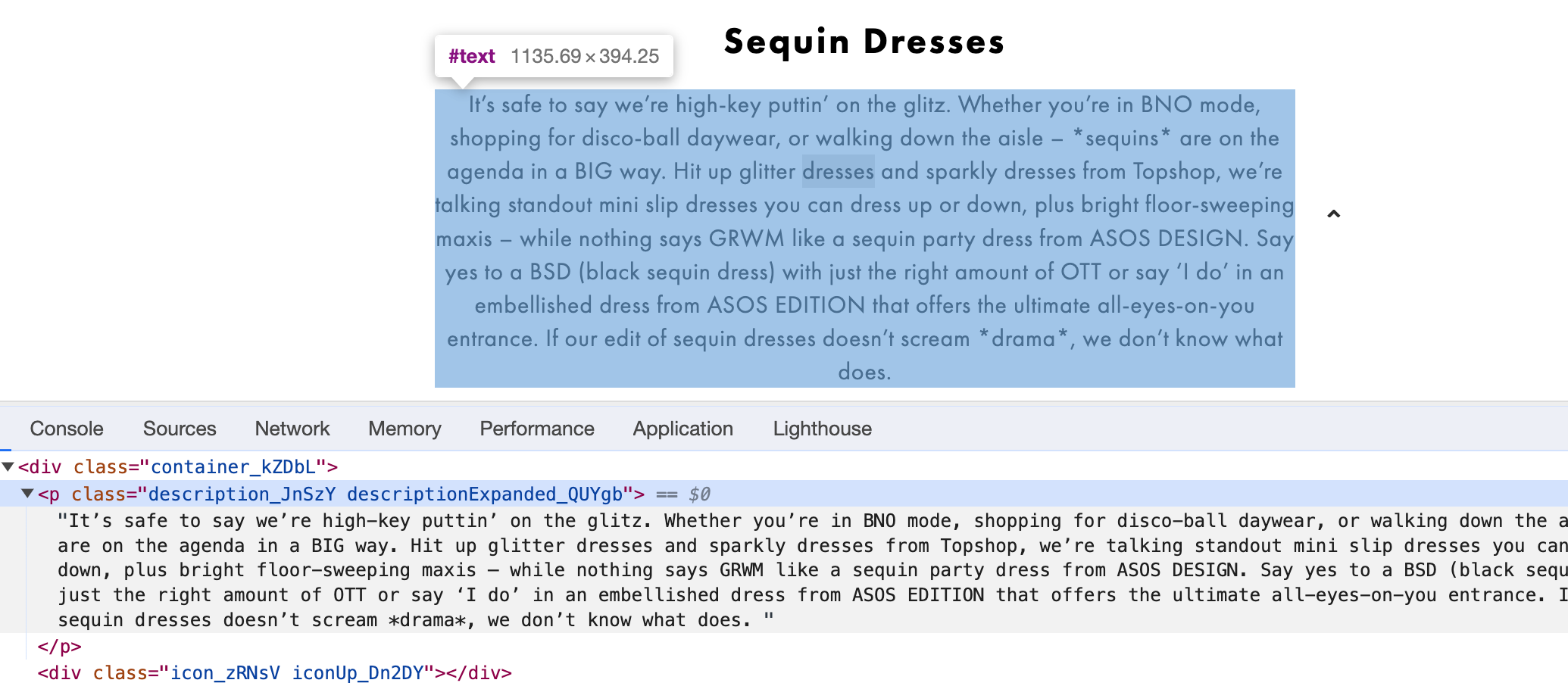
Tip: if there is a class with random looking letters and numbers appended to the end like the above screenshot (description_JnSzY) this class may update to something different at a later date and your extraction will no longer work. If you feel this may be the case with your extraction you may want to look for a different identifier or just match on the first part such as description_.
Why is this useful?
It allows you to:
Extract the schema element for ‘DatePublished’ and/or ‘DateModified’; or extract on-page elements.
Why is this useful?
It allows you to:
Extract the content of the <div> using the identifier, class or ID for the tags.
Why is this useful?
It allows you to check the categories/tags are being utilised appropriately.
Find a unique identifier for each type e.g how-to, video or listicle.
Why is this useful?
You can use this for segmentation or to compare performance and links for these different page types.
Look for a unique identifier such as a class, id or unique text that relates to a gated article or look for the schema "isAccessibleForFree": "False" which is the schema recommended for paywalled content. Keep in mind that some websites may have bot behaviour in place that keeps the page accessible to bots but not users.
Why is this useful?
It allows you to:
Extract the text of the buttons used within CTAs by pulling out the <button> text.
Why is this useful?
Get a list of topics and/or keywords and include those words within your extraction.
Why is this useful?
Extract the breadcrumbs elements using the class/ids or use the schema if present.
Why is this useful?
It allows you to:
Look for a class or identifier you can extract within the HTML like the platform name e.g Wordpress: <meta name="generator" content="WordPress 6.0.2">.
Why is this useful?
Identifying pages built with different CMS allows you to determine if an issue is sitewide or platform specific.
Get a list of known development websites and use an extraction method to pull the link and anchor text into an extraction.
Why is this useful?
Links to development domains can be classed as external URLs or disallowed by robots.txt making them hard to spot. A custom extraction can highlight these links quickly, making issues faster to fix.
Find a unique class or ID of each widget and extract that within the crawl.
Why is this useful?
It allows you to:
Now that you have your custom extractions set-up and they are bringing back the data you can start using the results of these alongside your standard crawl results.
If your crawler supports segmentation or something akin to task creation, you could choose to use your custom extractions to improve your issue reporting.
For example:
Your custom extractions can also help to support new SEO initiatives that you may be considering. Here are a couple of examples:
It might be that you are considering adding a noindex tag to out of stock PDPs. Here you can use your out of stock extraction to identify affected PDPs. With Search Console and GA sources added to the crawl, you can see both the traffic, and internal links to these out of stock pages.
The outcome of this may be that you decide to only noindex out of stock PDPs after they reach a low threshold of visits or clicks, and that you place out of stock PDPs at the end of category lists so that they are given less prominence. Going forward, this custom extraction can help you to keep track and monitor these pages.
If you are looking to get approval to add content to more PLPs, you could use an extraction to output the section with the custom content.
Once you have added this, you’ll know which PLPs have existing content and which are missing content. You are then able to incorporate GSC and GA data to look at the performance of the two types of pages. The extraction would also be handy to identify duplicate content issues and where pages have outdated content.
Your extractions can also be considered as part of your monitoring strategy. If you are extracting important elements vital to your website, you may want to consider setting up additional smaller or template based crawls around them.
For example, if your site has different page templates it's a good idea to take a few sample pages from each template and crawl them on a regular cadence along with your extractions. If your extraction monitoring a content element on category pages is suddenly empty after a code release, you’ll have an early warning of a potential problem.
Hopefully I’ve provided some new custom extraction ideas that you’d like to try out, but you definitely shouldn’t feel limited to just the examples in this article. The sky really is the limit, and if there is something within your website that a crawler doesn’t natively pull out but is in the rendered HTML then there is a good chance you’ll be able to extract it. Have fun!
